文脈を組む AI エージェントを作るために LLM のコンテキスト と Mastra のメモリを調べる
Fairy (AI エージェント) を作るメモまとめ > 文脈を組む AI エージェントを作るために LLM のコンテキスト と Mastra のメモリを調べる
バージョン:
現状の Fairy は会話の流れを汲んだレスポンスを生成することができない。 最高のアシスタントを自称する (させる?) からには、短期的・長期的問わず記憶力を発揮して、会話やサポートをして欲しい。
OpenAI の Conversation state
OpenAI API を使うとLLM (大規模言語モデル)を使ってプロンプトからテキストを生成することができる。 例えば Responses API だとこんな感じ。
const response = await client.responses.create({
model: "gpt-4.1",
input: "Write a one-sentence bedtime story about a unicorn.",
});
// Under the soft glow of the moon, Luna the unicorn danced through fields of twinkling stardust, leaving trails of dreams for every child asleep.
console.log(response.output_text);上記のようなテキストの生成は生成毎に独立している(ステートレス)ため、 会話の流れを汲んだレスポンスをもらうには会話の流れを丸ごと入力する必要がある 1。
const response = await openai.responses.create({
model: "gpt-4o-mini",
input: [
{ role: "user", content: "knock knock." },
{ role: "assistant", content: "Who's there?" },
{ role: "user", content: "Orange." },
],
});会話が続くにつれ input が雪だるま式に大きくなるわけだが、
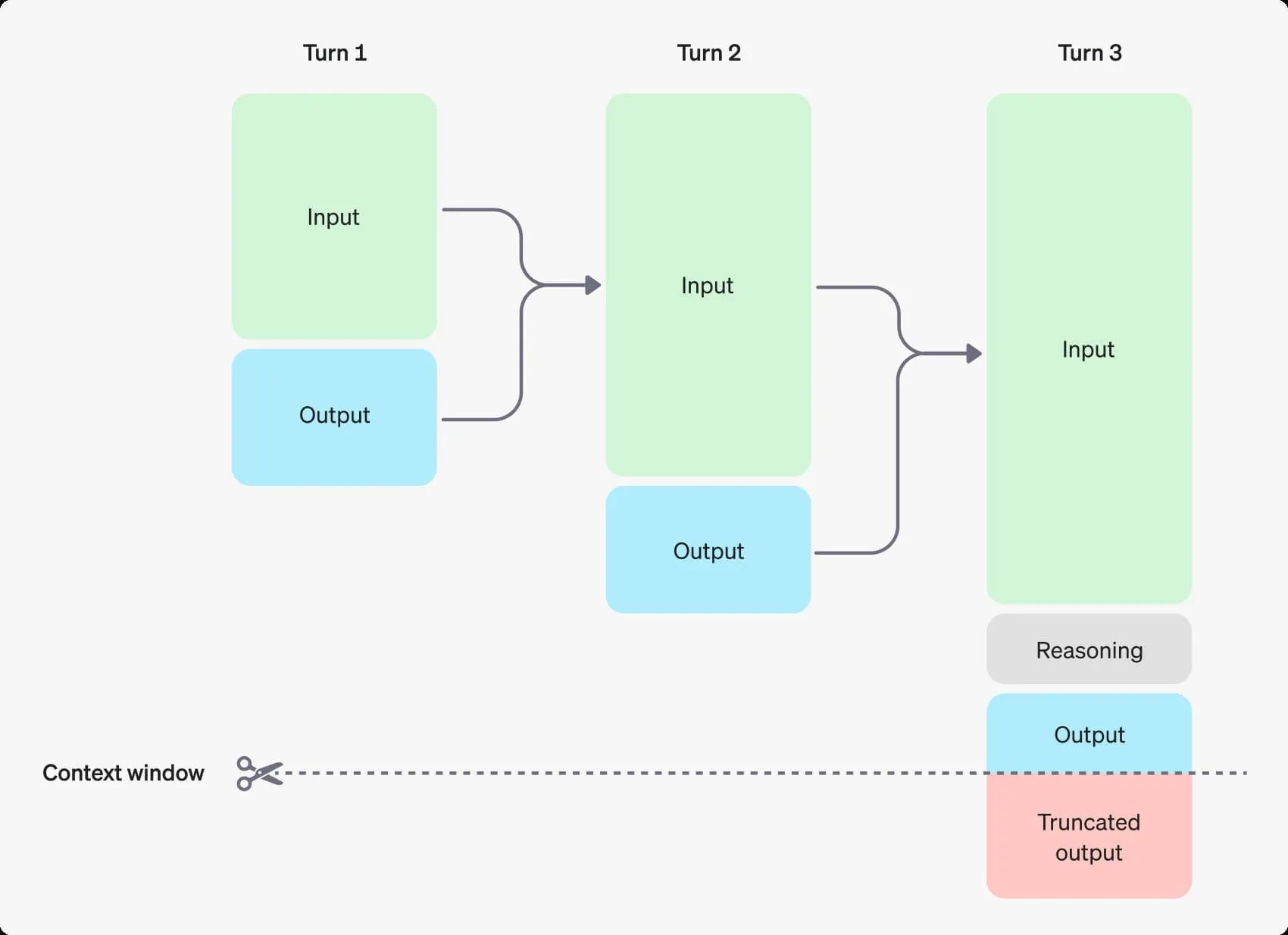
無限に増やせるかというとそうでもなく、出力トークンとコンテキストウィンドウの制限を考慮する必要がある。
コンテキストウィンドウとは 1回のリクエストで使用できるトークンの最大数 のこと。 この最大トークン数には以下の3つが含まれる:
- 入力トークン (Responses API の
inputに含める入力) - 出力トークン (プロンプトに応じてモデルが生成するトークン
- 推論トークン (推論が有効になっているモデルが回答を生成する前の思考に使うトークン)
図を見れば一発。
ref: https://platform.openai.com/docs/guides/conversation-state#managing-context-for-text-generation
チャットボット形式ならスレッドを分けることで入力トークン数をある程度抑えられるため、話の流れ(コンテキスト)を汲んだ出力も割と手軽に作れそう。 一方、私が作りたい Fairy はチャットボットではなく、常駐型?の AI アシスタント。コンテキストウィンドウの工夫は必須だ 🤔
Mastra の Memory
Mastra は ステートフルな会話を行うためにメモリという仕組み (クラス) を提供している。
メモリは、エージェントが利用可能なコンテキストを管理する方法であり、すべてのチャットメッセージをコンテキストウィンドウに凝縮したものです。
Mastra で作るエージェントが扱うコンテキストは3つに分けられる:
- システム指示とユーザーに関する情報(ワーキングメモリ)
- 最近のメッセージ(メッセージ履歴)
- ユーザーのクエリに関連する古いメッセージ(セマンティック検索)
さらに、コンテキストウィンドウに従ってコンテキストをトリムする仕組み(メモリプロセッサ)もある。
Mastra はメモリをスレッド毎に管理するため、 2つの識別子を使って会話履歴を識別する:
threadId: 特定の会話ID(例:support_123)resourceId: 各スレッドを所有するユーザーまたはエンティティID
おそらく、Fairy のために これらの ID を固定値にするのは現実的ではないのだろうな…。 コンテキストを共有させる/させないいい感じ (???) に制御して、コンテキストを構築する必要がある… 🤔
Mastra の Conversation History
OpenAI の Conversation state に相当するものを Mastra では Conversation History と呼んでいる。
デフォルトでは、Memoryインスタンスは現在のMemoryスレッドから最新の10件のメッセージを各新規リクエストに含めます。これにより、エージェントに即時の会話コンテキストが提供されます。
const memory = new Memory({ options: { lastMessages: 10, }, });
Mastra の Semantic recall
友人に先週末何をしたか尋ねると、彼らは「先週末」に関連する出来事を記憶の中から検索し、それから何をしたかを教えてくれます。これはMastraにおけるセマンティックリコールの仕組みに少し似ています。
☝️分かりやすい。
Semantic recall は Conversation history に含められない長期間の対話のコンテキストを維持することに役立つ。 ベクトル埋め込み (文章の意味・関係性を数値に変換する)) を使って類似性検索することで、 意味的に類似したメッセージをコンテキストに含めて LLM に送信する。
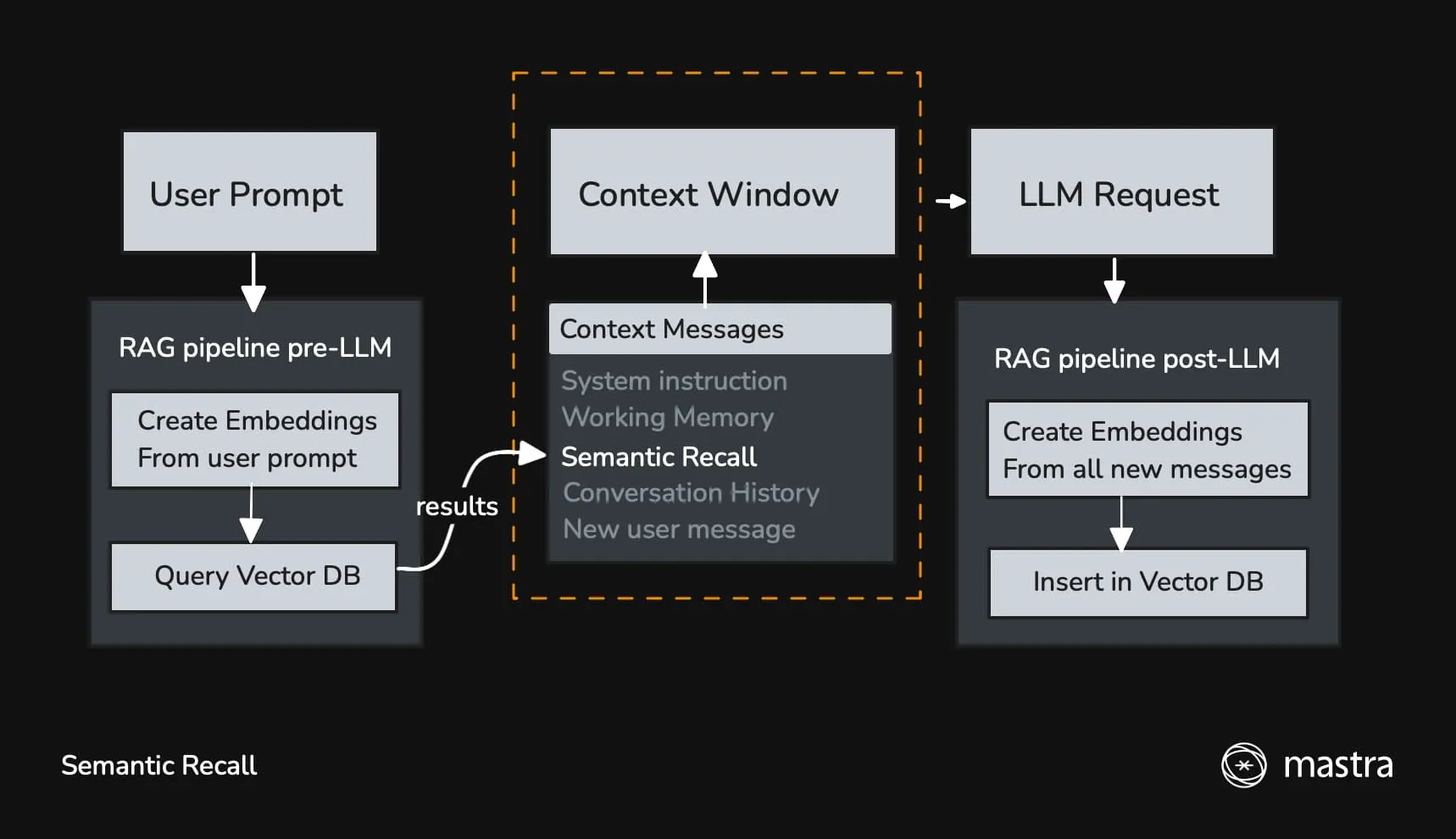
セマンティックリコールのふるまいは 2 つのパラメータで制御する:
topK: 意味的に類似したメッセージを何件取得するかmessageRange: 各一致に対してどれだけの周囲のコンテキストを含めるか
LLM のレスポンスを受け取った後はすべての新しいメッセージ(ユーザー、アシスタント、ツールコール/結果)をベクトル DB に保存して、 次のリクエスト時に参照出来るようにする。
Mastra の Working memory
ワーキングメモリは、エージェントが継続的に関連する情報を保存するために時間の経過とともに更新できる Markdownテキストのブロック です
👇️のように Markdown を使って、データをどのように構造化するかをエージェントに伝えることができる。
const memory = new Memory({
options: {
workingMemory: {
enabled: true,
template: `
# User Profile
## Personal Info
- Name:
- Location:
- Timezone:
`,
},
},
});エージェントは Thread での会話に従って Markdown が更新する。 あらかじめ作った見出し・リストにない情報をエージェントが保存するべきと判断した場合、いい感じ(?)に見出しやリストを追加する。
# User Profile
## Personal Info
- Name: T28
- Location:
- Timezone:
- Schedule:
- 12:00: 紅茶を淹れる
- 13:00: 人をもてなす
- Guest: 乙宗梢さん (紅茶が好き)エージェントがどのように Markdown を更新するかは instructions で指示することもできる。
Mastra の default template も参考になるかもしれない。
Working memory は mastra_thread テーブルの metadata カラムに保存されるため、threadId, resourceId 毎に保存される情報になる。
| id | resourceId | title | metadata | createdAt | updatedAt |
|---|---|---|---|---|---|
| uuid v4 | fairy | New Thread Name | {“workingMemory”: “ここに更新された markdown が入る”} | 2025-06-01T14:39:45.959Z | 2025-06-03T14:39:45.959Z |
DB でスキーマを定義せずに Markdown に書いていくメリットが今の時点だと全く分からない…。手軽さ?
Mastra の Memory processors
https://mastra.ai/ja/docs/memory/memory-processors
メモリプロセッサを使ってLLMに送信される前に処理が行える:
- コンテキストサイズの管理
- コンテンツのフィルタリング
- パフォーマンスの最適化
Mastra が提供している組み込みプロセッサ:
TokenLimiter- LLM のコンテキストウィンドウの上限超過を防ぐ
ToolCallFilter- LLM に送信するメモリメッセージからツールコールを削除する
- tool のやりとりをコンテキストから除外することでトークン数を節約できる
MemoryProcessor class を継承することでカスタムプロセッサを作ることも出来る ので、
これを使って “Fairy のためのいい感じのメモリ” を構築することになりそう 🤔
Footnotes
-
OpenAPI にはプラットフォーム側にレスポンスを保存させる仕組みがあり、デフォルトで有効 になっている。が、Mastra から直接 ↩